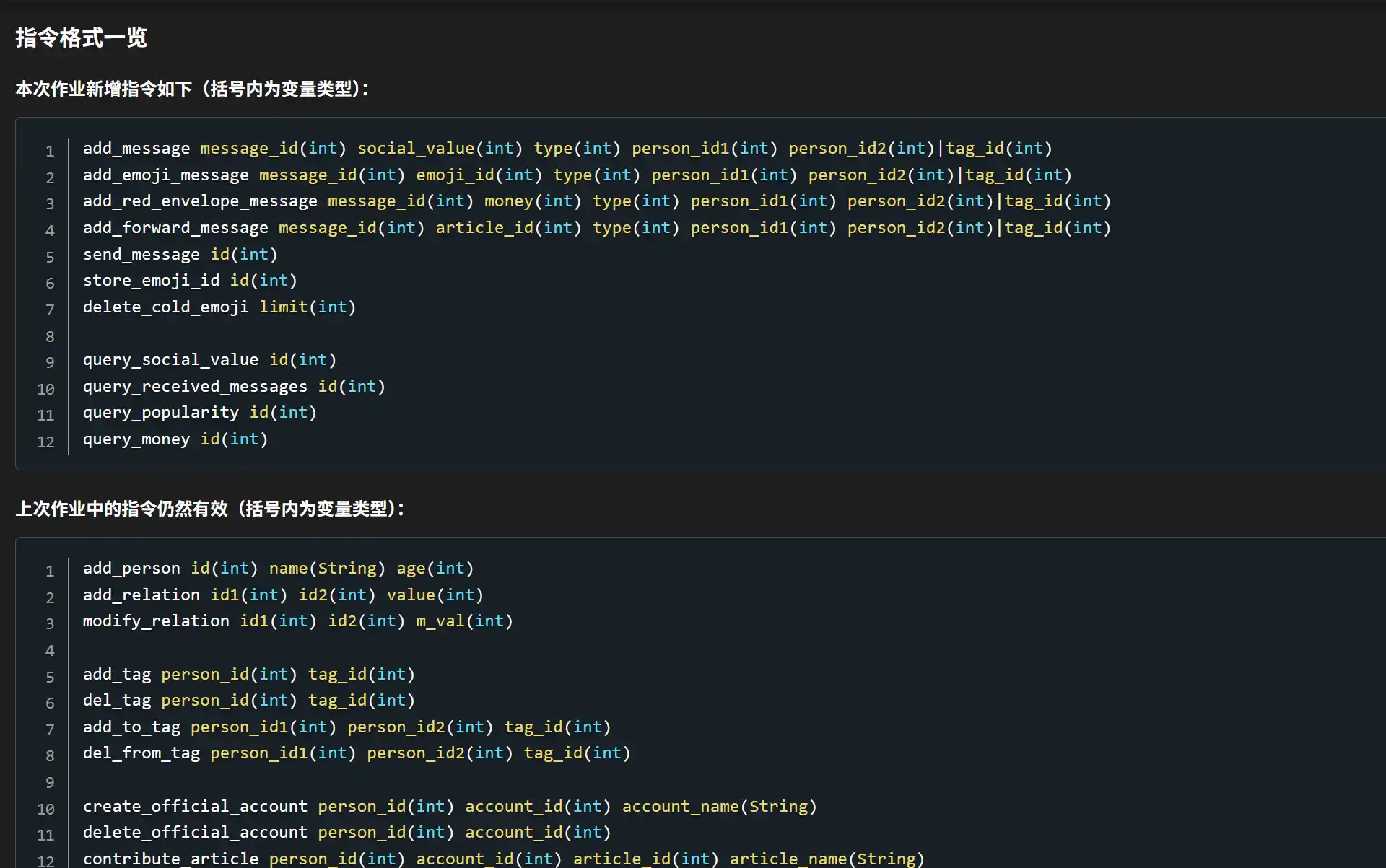
c static int pipe_close(struct Fd *fd) { // Unmap 'fd' and the referred Pipe. syscall_mem_unmap(0, fd); syscall_mem_unmap(0, (void *)fd2data(fd)); return 0; }
c // stdin should be 0, because no file descriptors are open yet if ((r = opencons()) != 0) { user_panic("opencons: %d", r); } // stdout if ((r = dup(0, 1)) < 0) { user_panic("dup: %d", r); }
在shell进程初始化的时候,由我们规定文件描述符0是标准输入而文件描述符1是标准输出。
Thinking 6.7
Q:
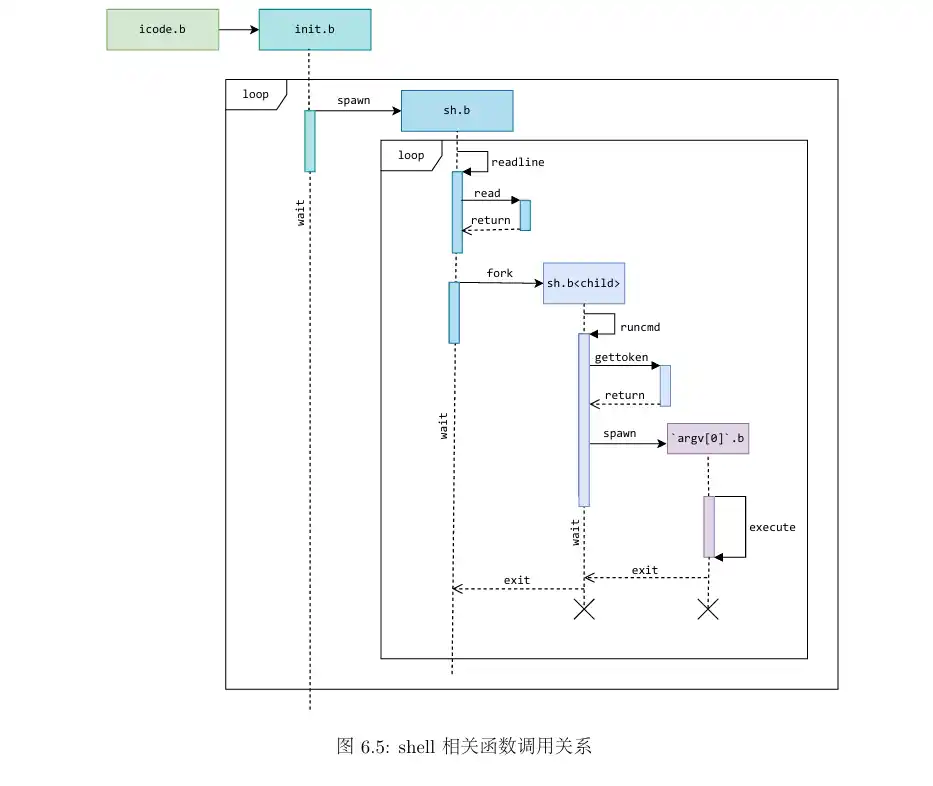
在 shell 中执行的命令分为内置命令和外部命令。在执行内置命令时shell不 需要fork 一个子 shell,如 Linux 系统中的 cd 命令。在执行外部命令时 shell 需要 fork 一个子shell,然后子 shell 去执行这条命令。 据此判断,在MOS 中我们用到的 shell 命令是内置命令还是外部命令?请思考为什么 Linux 的 cd 命令是内部命令而不是外部命令?
tex [00002803] is forked in shell! [1] [00002803] pipecreate 00002803 forked 00003004 [00002803] is calling a spawn function [00003004] is calling a spawn function 00002803 spawns 00003805 00003004 spawns 00004006 [00003805] destroying 00003805 [00003805] free env 00003805 i am killed ... [00004006] destroying 00004006 [00004006] free env 00004006 i am killed ... [00003004] destroying 00003004 [00003004] free env 00003004 i am killed ... [00002803] destroying 00002803 [00002803] free env 00002803 i am killed ...
staticint _pipe_is_closed(struct Fd *fd, struct Pipe *p) { // The 'pageref(p)' is the total number of readers and writers. // The 'pageref(fd)' is the number of envs with 'fd' open // (readers if fd is a reader, writers if fd is a writer). // // Check if the pipe is closed using 'pageref(fd)' and 'pageref(p)'. // If they're the same, the pipe is closed. // Otherwise, the pipe isn't closed.
int fd_ref, pipe_ref, runs; // Use 'pageref' to get the reference counts for 'fd' and 'p', then // save them to 'fd_ref' and 'pipe_ref'. // Keep retrying until 'env->env_runs' is unchanged before and after // reading the reference counts. /* Exercise 6.1: Your code here. (1/3) */ do { runs = env->env_runs; fd_ref = pageref(fd); pipe_ref = pageref(p); } while (runs != env->env_runs);
return fd_ref == pipe_ref; }
/* Overview: * Read at most 'n' bytes from the pipe referred by 'fd' into 'vbuf'. * * Post-Condition: * Return the number of bytes read from the pipe. * The return value must be greater than 0, unless the pipe is closed and nothing * has been written since the last read. * * Hint: * Use 'fd2data' to get the 'Pipe' referred by 'fd'. * Use '_pipe_is_closed' to check if the pipe is closed. * The parameter 'offset' isn't used here. */ staticintpipe_read(struct Fd *fd, void *vbuf, u_int n, u_int offset) { int i; structPipe *p; char *rbuf;
// Use 'fd2data' to get the 'Pipe' referred by 'fd'. // Write a loop that transfers one byte in each iteration. // Check if the pipe is closed by '_pipe_is_closed'. // When the pipe buffer is empty: // - If at least 1 byte is read, or the pipe is closed, just return the number // of bytes read so far. // - Otherwise, keep yielding until the buffer isn't empty or the pipe is closed. /* Exercise 6.1: Your code here. (2/3) */ p = (struct Pipe *)fd2data(fd); rbuf = (char *)vbuf; for (i = 0; i < n; ++i) { while (p->p_rpos == p->p_wpos) { if (_pipe_is_closed(fd, p) || i > 0) { return i; } syscall_yield(); } rbuf[i] = p->p_buf[p->p_rpos % PIPE_SIZE]; p->p_rpos++; } return n; // user_panic("pipe_read not implemented"); }
/* Overview: * Write 'n' bytes from 'vbuf' to the pipe referred by 'fd'. * * Post-Condition: * Return the number of bytes written into the pipe. * * Hint: * Use 'fd2data' to get the 'Pipe' referred by 'fd'. * Use '_pipe_is_closed' to judge if the pipe is closed. * The parameter 'offset' isn't used here. */ staticintpipe_write(struct Fd *fd, constvoid *vbuf, u_int n, u_int offset) { int i; structPipe *p; char *wbuf;
// Use 'fd2data' to get the 'Pipe' referred by 'fd'. // Write a loop that transfers one byte in each iteration. // If the bytes of the pipe used equals to 'PIPE_SIZE', the pipe is regarded as full. // Check if the pipe is closed by '_pipe_is_closed'. // When the pipe buffer is full: // - If the pipe is closed, just return the number of bytes written so far. // - If the pipe isn't closed, keep yielding until the buffer isn't full or the // pipe is closed. /* Exercise 6.1: Your code here. (3/3) */ p = (struct Pipe *)fd2data(fd); wbuf = (char *)vbuf; for (i = 0; i < n; ++i) { while (p->p_wpos - p->p_rpos == PIPE_SIZE) { if (_pipe_is_closed(fd, p)) { return i; } syscall_yield(); } p->p_buf[p->p_wpos % PIPE_SIZE] = wbuf[i]; p->p_wpos++; } // user_panic("pipe_write not implemented");
return n; }
T2
1 2 3 4 5 6 7
staticintpipe_close(struct Fd *fd) { // Unmap 'fd' and the referred Pipe. syscall_mem_unmap(0, fd); syscall_mem_unmap(0, (void *)fd2data(fd)); // syscall_mem_unmap(0, fd); return0; }
T3
交换顺序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
if (vpd[PDX(ova)]) { for (i = 0; i < PDMAP; i += PTMAP) { pte = vpt[VPN(ova + i)];
if (pte & PTE_V) { // should be no error here -- pd is already allocated if ((r = syscall_mem_map(0, (void *)(ova + i), 0, (void *)(nva + i), pte & (PTE_D | PTE_LIBRARY))) < 0) { goto err; } } } }
intspawn(char *prog, char **argv) { // Step 1: Open the file 'prog' (the path of the program). // Return the error if 'open' fails. int fd; if ((fd = open(prog, O_RDONLY)) < 0) { return fd; }
// Step 2: Read the ELF header (of type 'Elf32_Ehdr') from the file into 'elfbuf' using // 'readn()'. // If that fails (where 'readn' returns a different size than expected), // set 'r' and 'goto err' to close the file and return the error. int r; u_char elfbuf[512]; /* Exercise 6.4: Your code here. (1/6) */ if ((r = readn(fd, elfbuf, sizeof(Elf32_Ehdr))) != sizeof(Elf32_Ehdr)) { goto err; }
const Elf32_Ehdr *ehdr = elf_from(elfbuf, sizeof(Elf32_Ehdr)); if (!ehdr) { r = -E_NOT_EXEC; goto err; } u_long entrypoint = ehdr->e_entry;
// Step 3: Create a child using 'syscall_exofork()' and store its envid in 'child'. // If the syscall fails, set 'r' and 'goto err'. u_int child; /* Exercise 6.4: Your code here. (2/6) */ child = syscall_exofork(); if (child < 0) { r = child; goto err; }
// Step 4: Use 'init_stack(child, argv, &sp)' to initialize the stack of the child. // 'goto err1' if that fails. u_int sp; /* Exercise 6.4: Your code here. (3/6) */ if ((r = init_stack(child, argv, &sp))) { goto err1; }
// Step 5: Load the ELF segments in the file into the child's memory. // This is similar to 'load_icode()' in the kernel. size_t ph_off; ELF_FOREACH_PHDR_OFF (ph_off, ehdr) { // Read the program header in the file with offset 'ph_off' and length // 'ehdr->e_phentsize' into 'elfbuf'. // 'goto err1' on failure. // You may want to use 'seek' and 'readn'. /* Exercise 6.4: Your code here. (4/6) */ if ((r = seek(fd, ph_off)) < 0) { goto err1; } if ((r = readn(fd, elfbuf, ehdr->e_phentsize)) != ehdr->e_phentsize) { goto err1; } Elf32_Phdr *ph = (Elf32_Phdr *)elfbuf; if (ph->p_type == PT_LOAD) { void *bin; // Read and map the ELF data in the file at 'ph->p_offset' into our memory // using 'read_map()'. // 'goto err1' if that fails. /* Exercise 6.4: Your code here. (5/6) */ r = read_map(fd, ph->p_offset, &bin); if (r != 0) { goto err1; }
// Load the segment 'ph' into the child's memory using 'elf_load_seg()'. // Use 'spawn_mapper' as the callback, and '&child' as its data. // 'goto err1' if that fails. /* Exercise 6.4: Your code here. (6/6) */ r = elf_load_seg(ph, bin, spawn_mapper, &child); if (r != 0) { goto err1; } } } close(fd);
intparsecmd(char **argv, int *rightpipe) { int argc = 0; while (1) { char *t; int fd, r; int c = gettoken(0, &t); switch (c) { case0: return argc; case'w': if (argc >= MAXARGS) { debugf("too many arguments\n"); exit(); } argv[argc++] = t; break; case'<': if (gettoken(0, &t) != 'w') { debugf("syntax error: < not followed by word\n"); exit(); } // Open 't' for reading, dup it onto fd 0, and then close the original fd. // If the 'open' function encounters an error, // utilize 'debugf' to print relevant messages, // and subsequently terminate the process using 'exit'. /* Exercise 6.5: Your code here. (1/3) */ fd = open(t, O_RDONLY); if (fd < 0) { debugf("failed to open '%s'\n", t); exit(); } dup(fd, 0); close(fd); // user_panic("< redirection not implemented");
break; case'>': if (gettoken(0, &t) != 'w') { debugf("syntax error: > not followed by word\n"); exit(); } // Open 't' for writing, create it if not exist and trunc it if exist, dup // it onto fd 1, and then close the original fd. // If the 'open' function encounters an error, // utilize 'debugf' to print relevant messages, // and subsequently terminate the process using 'exit'. /* Exercise 6.5: Your code here. (2/3) */ fd = open(t, O_WRONLY | O_CREAT | O_TRUNC); if (fd < 0) { debugf("failed to open '%s'\n", t); exit(); } dup(fd, 1); close(fd); // user_panic("> redirection not implemented");
break; case'|':; /* * First, allocate a pipe. * Then fork, set '*rightpipe' to the returned child envid or zero. * The child runs the right side of the pipe: * - dup the read end of the pipe onto 0 * - close the read end of the pipe * - close the write end of the pipe * - and 'return parsecmd(argv, rightpipe)' again, to parse the rest of the * command line. * The parent runs the left side of the pipe: * - dup the write end of the pipe onto 1 * - close the write end of the pipe * - close the read end of the pipe * - and 'return argc', to execute the left of the pipeline. */ int p[2]; /* Exercise 6.5: Your code here. (3/3) */ r = pipe(p); if (r != 0) { debugf("pipe: %d\n", r); exit(); } r = fork(); if (r < 0) { debugf("fork: %d\n", r); exit(); } *rightpipe = r; if (r == 0) { dup(p[0], 0); close(p[0]); close(p[1]); return parsecmd(argv, rightpipe); } else { dup(p[1], 1); close(p[1]); close(p[0]); return argc; } // user_panic("| not implemented");